Data hosted on GitHub can be retrieved through the web interface or by cloning a repo to a local machine. Files can also be read directly from “raw” links. For example, in rudeboybert/fivethirty you can could use the following R code to read in one of the .csv files in the repo:
library(tidyverse)
read_csv("https://raw.githubusercontent.com/rudeboybert/fivethirtyeight/master/data-raw/antiquities-act/actions_under_antiquities_act.csv")## # A tibble: 344 x 9
## current_name states original_name current_agency action date year
## <chr> <chr> <chr> <chr> <chr> <chr> <dbl>
## 1 Devils Towe… Wyomi… <NA> NPS Estab… 9/24… 1906
## 2 El Morro Na… New M… <NA> NPS Estab… 12/8… 1906
## 3 El Morro Na… New M… <NA> NPS Enlar… 6/18… 1917
## 4 Montezuma C… Arizo… <NA> NPS Estab… 12/8… 1906
## 5 Montezuma C… Arizo… <NA> NPS Enlar… 2/23… 1937
## 6 Montezuma C… Arizo… <NA> NPS Enlar… 11/1… 1978
## 7 Montezuma C… Arizo… <NA> NPS Delet… 11/1… 1978
## 8 Petrified F… Arizo… Petrified Fo… NPS Estab… 12/8… 1906
## 9 Petrified F… Arizo… Petrified Fo… NPS Dimin… 7/31… 1911
## 10 Petrified F… Arizo… Petrified Fo… NPS Enlar… 11/1… 1930
## # … with 334 more rows, and 2 more variables: pres_or_congress <chr>,
## # acres_affected <chr>Reading files directly from GitHub requires a network connection. However, one of the advantages of doing so is that you don’t have to download a local copy of the data (i.e. with git clone). And if the data in the repository is subject to change, then you don’t have to manage keeping a local copy in sync.
As shown above, reading in a single file hosted on GitHub from its raw content URL is relatively straightforward. Reading multiple files and including pattern matching rules (via regular expressions) gets more complicated …
The read_repo() function described below is a convenient wrapper to do exactly that in R. This post will explain how the function works and will include an example of how it can be used in practice.
read_repo()
Generally speaking, to read in files from a repository you would have to do the following:
- Get paths to all files
- Subset paths to just those for files of interest
- Build paths to raw content for files of interest
- Read in files
read_repo() internally performs each step. In order to establish paths to the files, the function first constructs a request to the GitHub API. The GET request to the API (implemented with httr::GET()) is based on the “repo” argument passed to read_repo(). Next, the function parses the “path” from the API request response (via httr::content()). After parsing all paths in the repository, the list of paths can be reduced to those that match the “pattern” argument to read_repo(). The pattern can be a regular expression, which allows for more granular identification of files to read. With the list of paths, the function configures the raw content URLs. Finally, read_repo() maps a function (specified in “.f”) to these URLs. If the “to_tibble” argument is set to TRUE then this function will try to return a tibble, otherwise it will return a list. Any additional arguments passed to the read function can be included via the “…” parameter.
read_repo <- function(repo, branch = "master", pattern = NULL, to_tibble = TRUE, .f = read_csv, ...) {
## construct GET request from the repo and branch
api_request <- httr::GET(paste0("https://api.github.com/repos/",
repo,
"/git/trees/",
branch,
"?recursive=1"))
## extract path element from the API response
repo_files <- purrr::map_chr(httr::content(api_request)$tree, "path")
## if a pattern is passed use it to parse files of interest
if(!is.null(pattern)) {
repo_files <- repo_files[grepl(pattern, repo_files)]
}
## construct raw content URLs to files of interest
repo_files <- file.path("https://raw.githubusercontent.com",
repo,
branch,
repo_files)
## check that the value passed to .f is a function available in the environment
.f <- match.fun(.f)
## if to_tibble then use map_df() to compile results as a tibble
## otherwise return a list via map()
if(to_tibble) {
purrr::map_df(repo_files, .f = .f, ...)
} else {
purrr::map(repo_files, .f = .f, ...)
}
}EXAMPLE: CDC State FluSight forecast repository
The data hosted on the CDC State FluSight GitHub repository will be used to help demonstrate the usage of read_repo(). The State FluSight competition invites teams to submit predictive forecasts of influenza-like illness (ILI) across the United States and select territories. The CDC makes forecast submissions available in the repository.
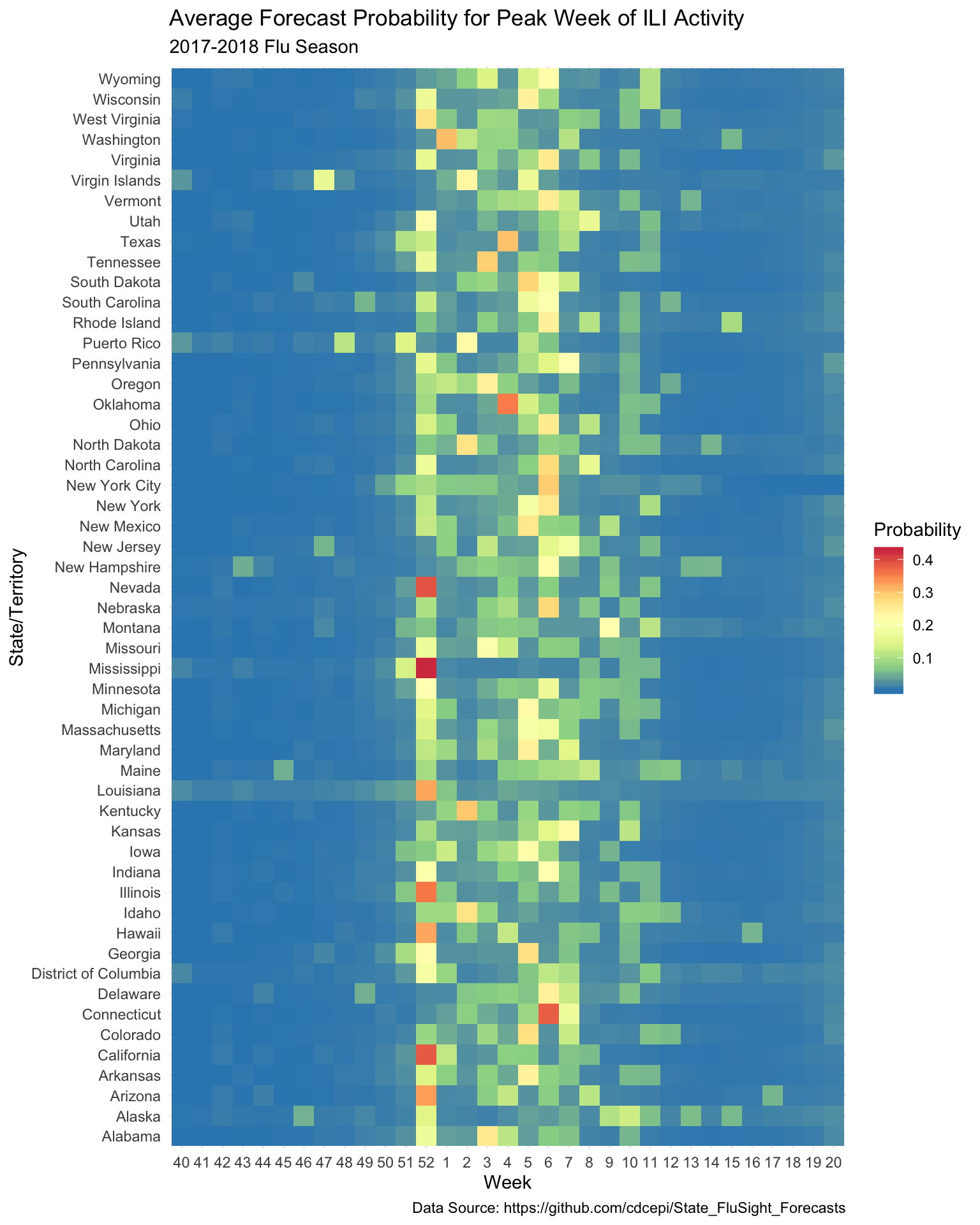
To see read_repo() in action, the code that follows will read all of the forecast submissions for the 2017-2018 season. In this case, the read function will be a custom wrapper around readr::read_csv() called read_forecast(). After defining that read function, it will be passed into read_repo() along with the pattern for selecting all .csv files in subdirectories of the 2017-2018/ directory in the repo. These subdirectories are named by team. The nice thing is that the pattern will match any team name so its not necessary to know what the team names are ahead of time. Last of all, the code will generate a plot of the average forecasted probability that each week will be the peak by state/territory.
## define a custom read function (read_forecast())
## wraps readr::read_csv()
## uses tryCatch in case there is a problem with one of the files
## also passes in "col_types = readr::cols()" to suppress messages
read_forecast <- function(file) {
tryCatch({
message(sprintf("Reading file: %s", file))
readr::read_csv(file, col_types = readr::cols())
},
error = function(e) {
message(sprintf("Unable to read file: %s", file))
}
)
}
## lots of files ... this will take a while
stateflu17_18 <- read_repo(repo = "cdcepi/State_FluSight_Forecasts",
pattern = "^2017-2018/.*/*.csv",
to_tibble = TRUE,
.f = read_forecast)
## did it work?
stateflu17_18 %>%
select(location:value) %>%
glimpse()## Rows: 13,120,512
## Columns: 7
## $ location <chr> "Alabama", "Alabama", "Alabama", "Alabama", "Alabama"…
## $ target <chr> "Season peak week", "Season peak week", "Season peak …
## $ unit <chr> "week", "week", "week", "week", "week", "week", "week…
## $ type <chr> "Bin", "Bin", "Bin", "Bin", "Bin", "Bin", "Bin", "Bin…
## $ bin_start_incl <dbl> 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 1…
## $ bin_end_notincl <dbl> 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 2…
## $ value <dbl> 0.0000000, 0.0000000, 0.0000000, 0.0000000, 0.0000000…stateflu17_18 %>%
select(location:value) %>%
filter(target == "Season peak week" & type == "Bin") %>%
group_by(location, bin_start_incl) %>%
summarise(value = mean(value), .groups = "drop") %>%
mutate(week = factor(as.character(bin_start_incl), levels = c(as.character(40:52), as.character(1:20)))) %>%
rename(Probability = value) %>%
ggplot(aes(week, location)) +
geom_tile(aes(fill = Probability)) +
scale_fill_distiller(palette = "Spectral") +
theme_minimal() +
labs(x = "Week",
y = "State/Territory",
title = "Average Forecast Probability for Peak Week of ILI Activity",
subtitle = "2017-2018 Flu Season",
caption = "Data Source: https://github.com/cdcepi/State_FluSight_Forecasts")